Recently there was a question posed on the Educational and Developmental Psychology Networking Australia (EDPNA) Facebook group which I found very intriguing. A child had been assessed using the Wechsler Intelligence Scale for Children – Fouth Edition (WISC-IV; for individuals 6-16 years) approximately 10 years before, and had been reassessed using the Wechsler Adult Intelligence Scale (WAIS-IV; for individuals aged 16 and older). We typically expect cognitive abilities to be stable across the lifespan, when comparing to similar-aged peers. But in this case, the young person’s scores were significantly different, and there was no obvious reason for the difference. So I started wondering if differences in ability scores across time could possibly be explained as a consequence of error rather than an actual change.
I had a quick look at the literature and didn’t find any great answers (it is a very specific question of 10 year temporal stability and correlation between types of tests after all). So I decided to apply some statistical analysis of my own, and in doing so get to practice using R, which I have been trying to teach myself in my spare time. For this to work, a number of assumptions have to be made – let me know what you think of these assumptions.
We start with simulated data (using the simulation code in SPSS discussed here) because there is no real case data available. 1000 cases are randomly generated with a whole digit score which has a mean of 100 and standard deviation of 15 (just like an index score – in fact, this is a WISC-IV index score, which one doesn’t matter). Let’s assume that the true correlation between the WISC-IV and WAIS-IV is .90 in the population. That’s a pretty high true correlation, maybe not realistic but good enough as a starting point. So we generate a new score for our 1000 simulated cases which has a .90 correlation with the original score – this is our WAIS-IV index score. In the first image at step 1, you can see this relationship plotted.
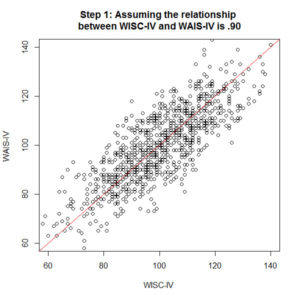
Unfortunately there is more to worry about than just the relationship between the WISC-IV and WAIS-IV. We need to account for how stable the scores are over time, or test-retest reliability. Let’s assume that the temporal stability of the index scores are .90 over 10 years – again a really high score, and probably very generous. Temporal stability and the WISC/WAIS relationship errors aren’t related to each other, so we need to combine the error. .90 relationship error multiplied by .90 temporal stability error (working in the assumption that the error is independent, and therefore compounding) gives us a new relationship between the WISC-IV and WAIS-IV across 10 years of .81. A third index score is simulated, which correlates .81 with our original WISC-IV index score. This is the revised WAIS-IV score after accounting for stability and relationship, and can be seen in step 2. That graph is getting a little messy.
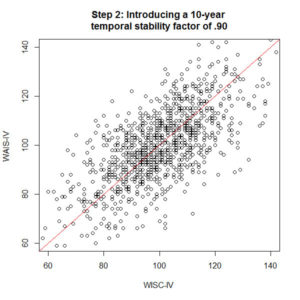
But hang on, so far we have been assuming that index scores are perfect. A score of 100 is actually [95-105] with a 95% confidence interval (using a crude average). The confidence interval is constructed by taking the standard error of measurement (SEM), multiplying it by two, and adding/subtracting this score to/from the index score to create a range. If we work backwards through this calculation, the SEM is 2.5 standard score points, or 0.167 of a standard deviation. If we take this error rate and subtract it from the “perfect” relationship a sample score would have with the population score (no measurement error), then we have a new relationship of .83 (1 – 0.167) between the achieved score and the true score. We should take this into account in considering the relationship between our simulated index scores over time, so a new index score is generated, which is .90 relationship error multiplied by .90 temporal stability error multiplied by .83 measurement error = .56 (now our compounding error is starting to look serious). You can see this plotted in step 3. This step is perhaps even a little conservative, because we really only have applied the measurement error for one measurement (say the WISC-IV) and could apply it to both to be really fair. But we are being generous at the moment.
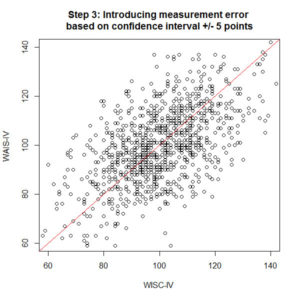
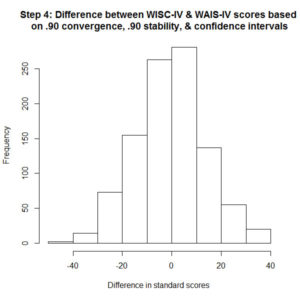
Looking at all that noise isn’t really helping to address the original question. By how much can an index score vary over 10 years, between the WISC-IV and WAIS-IV, including measurement error? If we take the difference between the final simulated WAIS-IV index score and the first simulated WISC-IV index score, and plot it in a histogram, we can see how large the change is for all the simulated cases. This is shown in step 4. Out of a sample of 1000, about 150 had WAIS-IV index scores which were 20 standard score points lower than their original WISC-IV index scores. A further 75 simulated cases had scores 30 points lower, and about 10 cases with 40 point differences. So about 23.5% of the sample appear to lose 20 or more standard score points (with similar numbers also showing gains).
This simulation is based on some pretty optimistic figures. I didn’t find figures on the relationship between WISC-IV and WAIS-IV index scores (but never really tried too hard), but what if it was only .80? And what if the 10 year temporal stability was also only .80? Both of these scores are still really high. A histogram modelling that shows about 26% of the sample lost 20 or more standard score points. If the relationship was .70 for each of those parameters, about 28.5% of the sample lost that much.
Now consider that this simulation is for only one index score. The WISC-IV has four index scores, and even with optimistic parameters of .90, there is a 23.5% chance that each of them may demonstrate a 20 or more point loss. Those are pretty high odds that you will find at least one index score that varies quite significantly within any individual over 10 years and between types of tools. And this ignores any changes in typical development, incident or injury, medication, diagnosis, sleep, diet, or any other factor that you can think of which might influence a cognitive ability score.
This is of course just a simulation study, but the mechanics of it are accurate. If anyone finds actual parameters for 10 year test-retest stability, or the relationship between WISC-IV and WAIS-IV, we could plug them in and simulate it with 10000 cases if needed. But it seems to indicate pretty conclusively to me that even if we are optimistic and everything relates to everything really strongly, there is still a pretty high chance of what looks like a significant change in cognitive ability scores across time could be nothing more than error.
